人类进步的阶梯
算法和数据结构
滑动窗口go模板
nSum问题解决模板
【链表问题】
21. 合并两个有序链表
23. 合并 K 个升序链表
19. 删除链表的倒数第 N 个结点
876. 链表的中间结点
141. 环形链表
redis
tx
一些QA
【Redis】
rehash
击穿、穿透、雪崩
【计算机网络】
TCP
【Mysql】
索引
资料索引
本文档使用 MrDoc 发布
-
+
首页
索引
## B树和B+树 - [B树](https://www.cs.usfca.edu/~galles/visualization/BTree.html) - [B+树](https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html) ### B树和B+树有什么区别? B树: 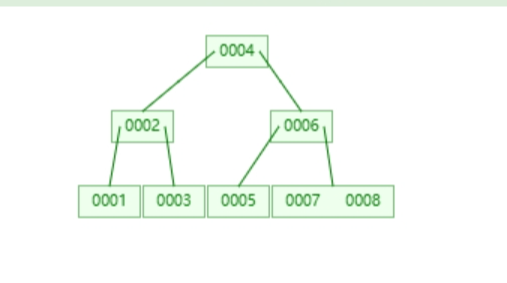 B+树: 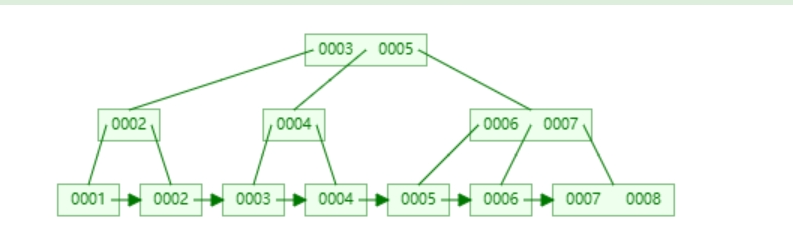 - 共同点:排序树、一个结点有多个元素(Degree) - B+树特点:叶子结点有指针、非叶子结点的数据都冗余了一份到叶子节点 B+树相当于是B树的升级版 ### Innodb中的B+树有什么特点 - 双向指针 - 没有数据冗余 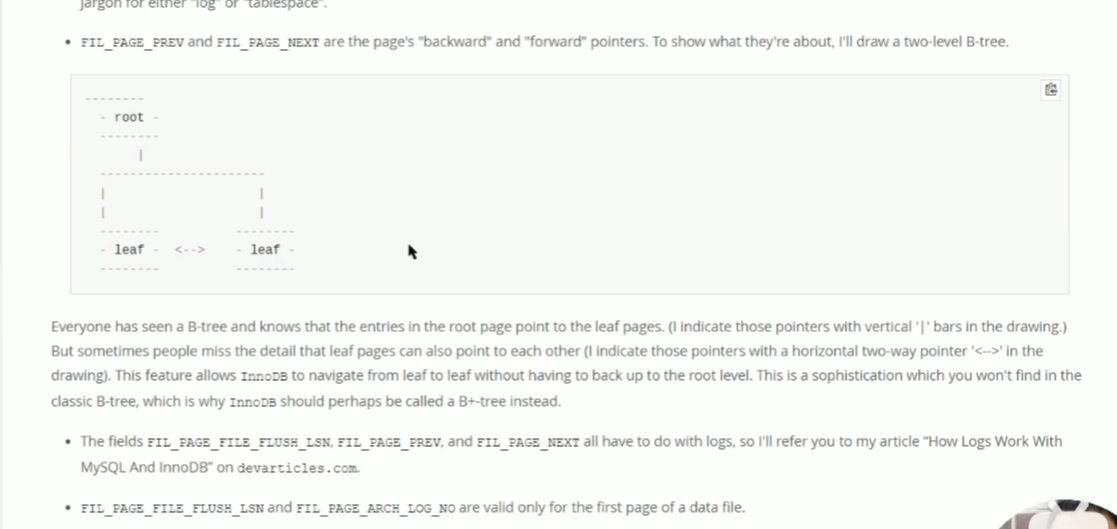 ## Innodb中的Page 默认大小是 16384 字节,就是 16kb - 向磁盘读写的最小单位是一页 - 是一个逻辑单位 页结构: 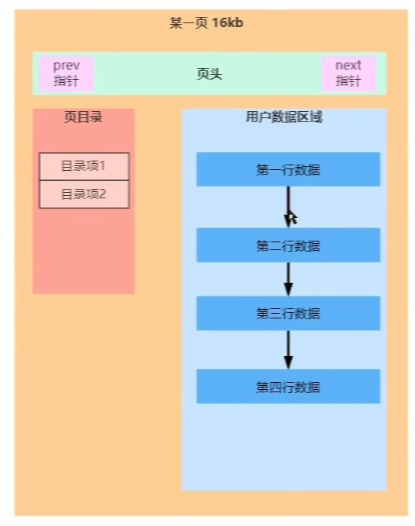 ## 高度为3的B+树,可以存储多少条数据 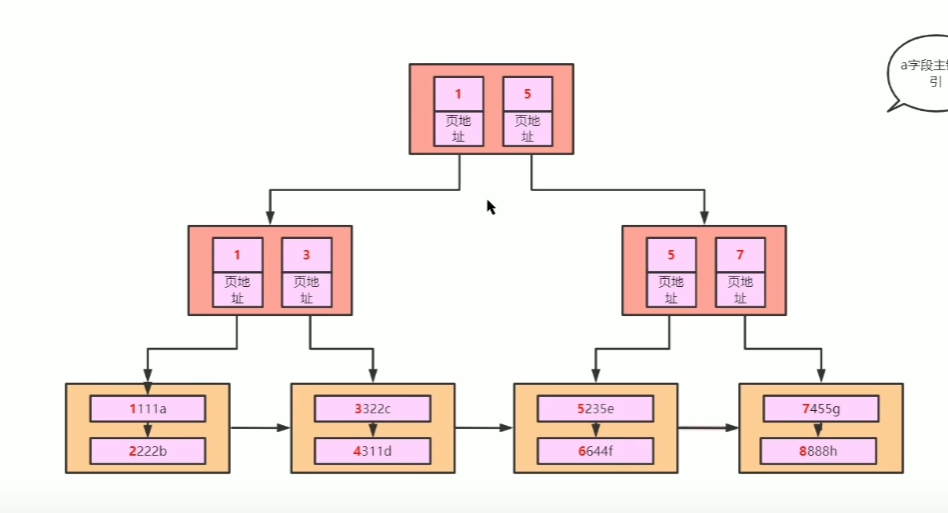 假设一行数据大小为 `1kb`, 索引为`int`,一个索引指针的大小为 `4b` + `6b` = `10b` 第一层根节点可以存,16384 / 10 = 1638 个索引 第二层为 1638 个节点,1638 * 1638 第三层叶子节点,每个叶子节点可以存储 16384 / 1024 = 16 行数据 所以整颗B+树存储的行数为 1638 * 1638 * 16 = 42,928,704 ## 聚集索引和非聚集索引 - 上面的叫索引页,下面的叶子结点是数据页,聚集索引就是索引页和数据页存在一起 - 聚集索引表示数据的物理位置 - innodb中的聚集索引是主键索引 - 非聚集索引的叶子结点不存储整行数据,只存储索引的值和主键的指针,查询非索引字段需要**回表**(就是通过主键索引再查一次) 聚集 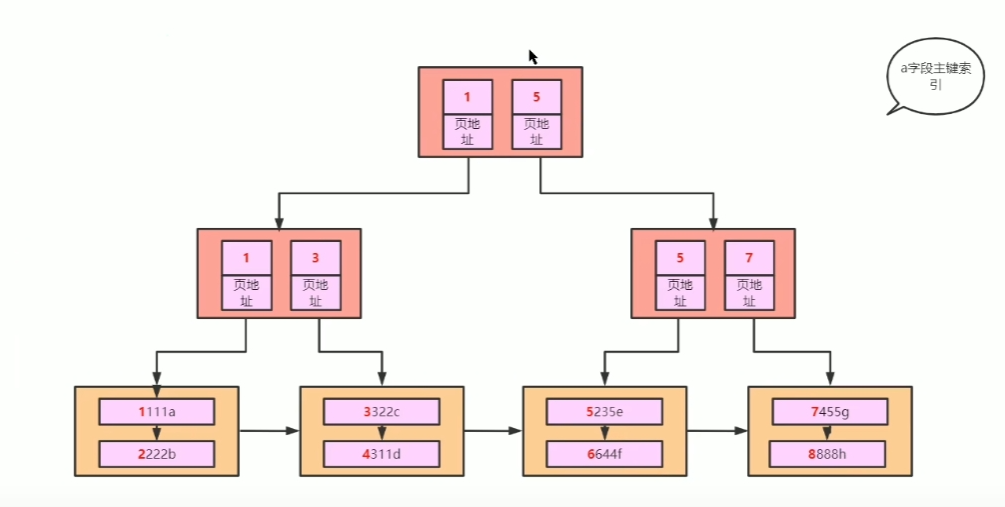 非聚集 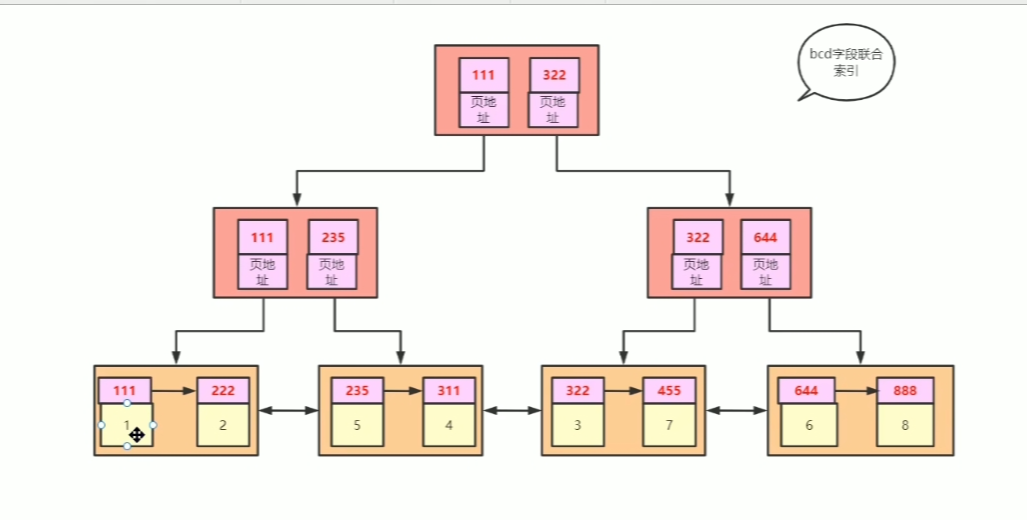 ## 最左前缀原则 - 和`where`条件的顺序无关,和`where`条件中有没有给联合索引的最左字段有关 - `b-c-d`三个字段联合索引,`where b=1 and d=1`可以走索引,`where c=1 and d=1`不能走索引,主要是看能不能和索引中的值进行比较 ## 范围查找索引失效 - 主要是发生在非聚集索引上,范围比较大,查询的字段不止索引字段时,需要回表多次,mysql可能会判断全表扫描更快,会选择走全表扫描 - 可以使用`FORCE INDEX (索引名称)` 、 `USE INDEX (索引名称)`  ## 覆盖索引 - 不需要回表,只需要索引中的数据就可以满足查询 - 比如: `b-c-d`联合索引,查询`select b,c,d from table` ## orderBy为什么会导致索引失效 mysql判断在内存中排序比从索引中查询再回表更快 ## 类型转换 字符转数字: ```sql select 'a'=0; -- 1 select 'b'=0; -- 1 select '123'=123; -- 1 ``` 可以转换成数字的,转为数字;其他的全部转为0; 有一个`varchar(20)`的字段`e`,使用`select * from table where e=1` 不走索引,会把表里的字符都转成数字去和1比较; 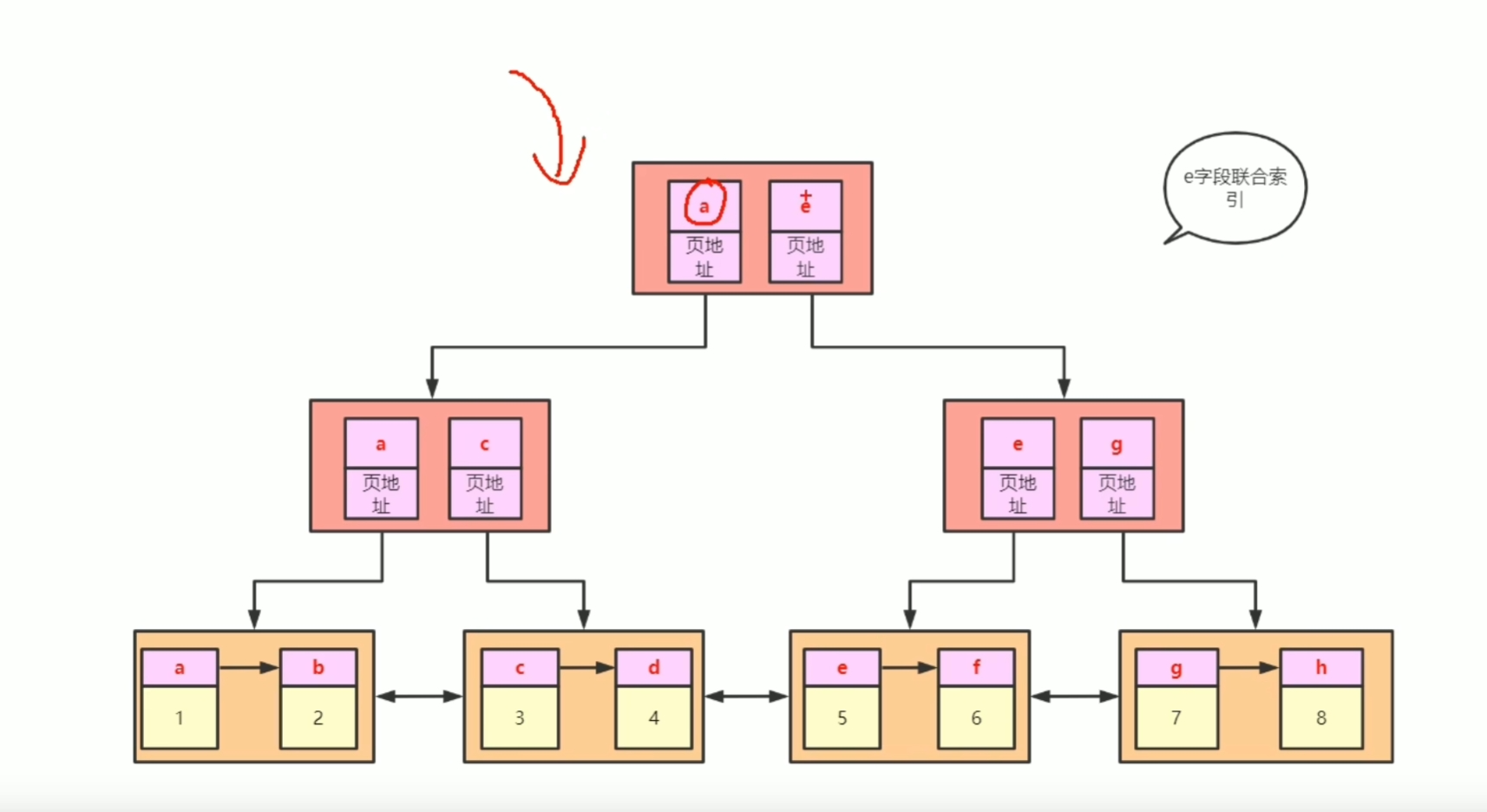 **只要对字段进行了操作,就没办法走索引**,因为需要重建B+树
adminadmin
2024年6月19日 00:51
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码